DeepSeek Unveils V4-Flash and V4-Pro in Official Preview, Expanding Its Open-Source AI Push
By Administrator
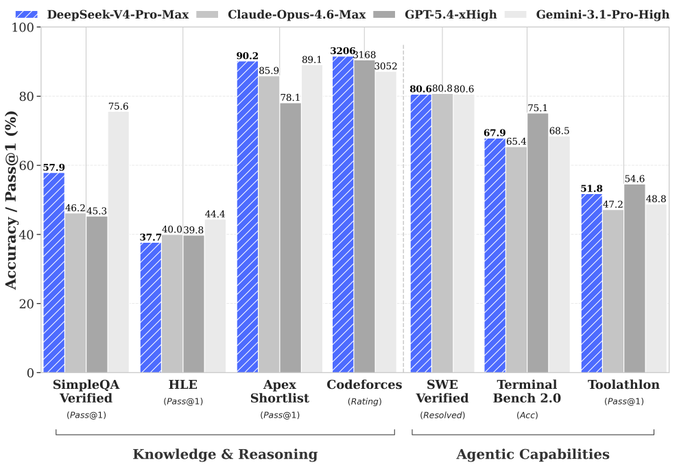
DeepSeek has released preview versions of DeepSeek-V4-Flash and DeepSeek-V4-Pro, a new open-source model family with a 1 million-token context window, updated reasoning modes, and API availability confirmed through the company’s official documentation.
DeepSeek has formally introduced DeepSeek-V4-Flash and DeepSeek-V4-Pro, launching the new models as preview releases through its official Hugging Face repositories and listing them in its public API documentation on April 24, 2026. The release marks the company’s next major open-source model family and positions the V4 series as DeepSeek’s latest attempt to narrow the gap with leading closed-source systems in coding, reasoning, long-context handling, and agentic workflows.
The release appears to be official rather than speculative: the models are published under DeepSeek’s verified Hugging Face account, the company’s API docs now list both model names as live options, and Reuters separately reported the preview launch the same day, noting that DeepSeek has not yet given a timeline for finalizing the models.
A two-tier V4 lineup with million-token context
According to DeepSeek’s published model card, the V4 series consists of two Mixture-of-Experts language models: DeepSeek-V4-Pro with 1.6 trillion total parameters and 49 billion activated parameters, and DeepSeek-V4-Flash with 284 billion total parameters and 13 billion activated parameters. DeepSeek says both support a context length of one million tokens, placing long-context processing at the center of the release.
The company also published both base and instruction-tuned variants, with downloadable weights available under the MIT license. In practical terms, that makes the V4 family not just an API announcement but also a full open-weight release aimed at developers, researchers, and enterprises that want local or customized deployment options.
| Model | Total Parameters | Activated Parameters | Context Length | Published API Output Price |
|---|---|---|---|---|
| DeepSeek-V4-Flash | 284B | 13B | 1M tokens | $0.28 per 1M output tokens |
| DeepSeek-V4-Pro | 1.6T | 49B | 1M tokens | $3.48 per 1M output tokens |
DeepSeek’s API documentation shows that both models are available through OpenAI-format and Anthropic-format compatible endpoints, a decision that lowers switching costs for developers already using those ecosystems. The same documentation says both V4 models support thinking and non-thinking modes, JSON output, tool calls, and chat prefix completion, while FIM completion is limited to non-thinking mode.
What DeepSeek says changed in V4
DeepSeek’s technical summary highlights three core architectural changes behind the new family. First is a Hybrid Attention Architecture combining Compressed Sparse Attention and Heavily Compressed Attention, which the company says is meant to improve long-context efficiency. In its own published comparison, DeepSeek says that in a 1 million-token context setting, DeepSeek-V4-Pro requires 27% of the single-token inference FLOPs and 10% of the KV cache used by DeepSeek-V3.2.
Second, the company says it added Manifold-Constrained Hyper-Connections, described as a way to strengthen residual connections and improve signal propagation across layers. Third, DeepSeek says it used the Muon optimizer to improve convergence speed and training stability.
DeepSeek also states that both V4 models were pre-trained on more than 32 trillion tokens and then passed through a multi-stage post-training pipeline involving supervised fine-tuning, reinforcement learning with GRPO, and on-policy distillation. Those details matter because they frame V4 not as a minor update, but as a broader architecture-and-training overhaul aimed at pushing open models into more demanding reasoning and software tasks.
Performance claims are ambitious, but they remain vendor-reported
The strongest claims in the release come from DeepSeek’s own benchmark tables, and they should be read in that context. DeepSeek describes V4-Pro-Max as its most advanced reasoning configuration and says it delivers top-tier coding performance while narrowing the gap with leading closed-source models on reasoning and agentic tasks. The company also says V4-Flash-Max can achieve reasoning performance comparable to the Pro variant when given a larger thinking budget, though it acknowledges that the smaller model trails on knowledge-heavy tasks and the most demanding agent workflows.
In DeepSeek’s published results, V4-Pro-Max posts 87.5 on MMLU-Pro, 93.5 on LiveCodeBench Pass@1, 80.6 on SWE Verified, and 83.5 on MRCR 1M. In the same comparison table, V4-Flash-Max reaches 86.2 on MMLU-Pro, 91.6 on LiveCodeBench, 79.0 on SWE Verified, and 78.7 on MRCR 1M. Those numbers suggest that DeepSeek is trying to make Flash a serious lower-cost option rather than a stripped-down side model.
Still, the release materials do not provide an independent third-party audit of these benchmark claims. Where DeepSeek compares V4-Pro-Max with frontier closed models from rivals, those comparisons are DeepSeek’s own published evaluations, not external certification. For a news reader, the most defensible conclusion is that DeepSeek is presenting V4 as a major performance step forward, but broader market validation will depend on developer testing and third-party benchmarking in the weeks ahead.
Pricing and product strategy point to a broader API reset
The commercial structure of the release is almost as significant as the model launch itself. DeepSeek’s pricing page lists DeepSeek-V4-Flash at $0.028 per 1 million cached input tokens, $0.14 per 1 million uncached input tokens, and $0.28 per 1 million output tokens. DeepSeek-V4-Pro is priced much higher at $0.145 cached input, $1.74 uncached input, and $3.48 output per 1 million tokens.
That pricing creates a clear split inside the lineup: Flash is positioned as the lower-cost, higher-throughput workhorse, while Pro is the premium tier for heavier reasoning and more demanding agent tasks. The structure mirrors the tiered strategies now common across the broader AI industry, but DeepSeek is pairing that approach with open weights and long-context availability.
The API transition also appears to be broader than a simple model addition. On DeepSeek’s official quick-start page, the company says deepseek-chat and deepseek-reasoner will be deprecated on July 24, 2026, and for compatibility they map to the non-thinking and thinking modes of DeepSeek-V4-Flash. That suggests V4-Flash is not just a new option; it is becoming a central part of DeepSeek’s mainstream API offering.
Huawei support adds strategic weight to the launch
Beyond benchmarks and pricing, the release carries industrial and geopolitical significance. Reuters reported that the new model was launched as a preview adapted for Huawei chip technology, and that Huawei said it had worked closely with DeepSeek so the V4 series could run across its Ascend high-performance systems. Reuters also reported that DeepSeek did not disclose which processors were used to train the model.
That detail matters because DeepSeek has been at the center of wider debate over compute supply, export controls, and China’s drive to reduce dependence on U.S. semiconductor technology. In that context, Huawei compatibility makes the V4 launch more than a model refresh: it also becomes part of the broader push to build a more self-sufficient Chinese AI stack.
At the same time, Reuters noted that the preview arrived amid intensifying U.S.-China tensions over AI intellectual property and chip access. Those issues remain unresolved, and they sit outside the technical merits of the model itself. But they are now part of the backdrop against which every major DeepSeek release is judged.
What is confirmed, and what remains open
What is clearly established now is that DeepSeek has officially released preview versions of V4-Flash and V4-Pro, that both are available in the company’s API and open-weight repositories, and that the launch is tied to a new million-token, long-context model family with tiered pricing and reasoning modes.
What remains uncertain is how quickly the preview will mature, how closely third-party testing will match DeepSeek’s published benchmark claims, and when DeepSeek plans to move the V4 family from preview to final release. Reuters reported that the company has not provided a completion timeline, which means the market is getting an important model launch, but not yet a finished product.
For now, the V4 release shows DeepSeek continuing the strategy that made it one of the most closely watched names in AI: ship open models, push aggressive efficiency claims, offer developer-friendly pricing, and challenge the idea that top-tier AI progress must come only from closed, U.S.-based platforms.